
EU:n ilmastopolitiikan vaikutukset Suomen makrotalouteen
Oxford Economicsin Akava Worksille laatima arviointiraportti tarkastelee EU:n ilmastopolitiikan taloudellisia vaikutuksia Suomeen. Se osoittaa, että puhtaaseen energiaan siirtyminen antaisi vahvan kasvusysäyksen Suomen talouteen. Selvitys vertailee kolmea näkymää ja niiden taloudellista merkitystä.

Näkökulmia tekoälyyn, osa 6 – Nikolaj Tatti: Tekoälyn rajoitukset ja väärinkäyttö
Artikkeli käsittelee tekoälyn rajoitteita ja väärinkäytön mahdollisuuksia. Siinä tarkastellaan, millä tavoilla tekoälymallit voivat esimerkiksi aiheuttaa syrjintää, levittää virheellistä tietoa ja joutua jopa manipulaation kohteeksi. Artikkelissa korostetaan ihmisen merkitystä mallintajana sekä tekoälyn toimintatapojen, käytön ja rajoitteiden ymmärtämisen tärkeyttä.

Näkökulmia tekoälyyn, osa 2 – Riku Neuvonen: Tekijänoikeudella suojattu aineisto tekoälyn koulutuksessa
Tällä hetkellä tekoäly on vallitseva ilmiö monilla aloilla. Samalla siihen liittyy myös monia pelkoja ja uhkakuvia. Erityisesti luovilla aloilla sen pelätään ja uskotaan korvaavan luovan työn tekijät. Keskustelusta usein kuitenkin unohtuu, että tekoälyä koulutetaan olemassa olevan aineiston perusteella. Onko tämä tekijänoikeuden kannalta sallittua? Entä voiko tekoäly olla tekijänoikeuden suojaan oikeutettu tekijä?
Näkökulmia tekoälyyn, osa 1 – Arto Klami: Miksi tekoäly oppi näkemään ja juttelemaan nyt ja mihin se riittää?
Vielä muutama vuosi sitten moni tekoälytutkijakin arvioi, että sujuvasti keskusteleva tekoäly on vielä kaukainen tulevaisuudenhaave. Nyt tarjolla on kuitenkin toinen toistaan vakuuttavammin toimivia palveluita ja moni meistä käyttää niitä jo päivittäisen työnsä tehostamiseen. Mistä tässä läpimurrossa on kyse ja miten se saatiin aikaan?
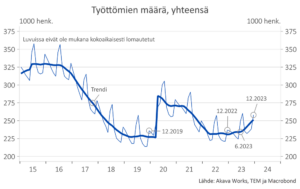
Työttömyys- ja lomautuskatsaus 1/2024: Huonoja enteitä
Työttömien ja lomautettujen määrät kasvavat edelleen. Korkeakoulutettujen työttömyys lähestyy korona-ajan korkeimpia lukuja ja saavuttanee ne keväällä. Tämä on huono enne, joka ennakoi työttömyyden laajempaa kasvua. Vastavalmistuneiden työttömyys kasvaa selvimmin ylemmän korkea-asteen suorittaneilla korkeakoulutetuilla. Katsauksen luvut ovat joulukuun 2023 lopulta.

Kustannuskilpailukykyvertailun esittelylähetys
Millainen on Suomen kustannuskilpailukyky suhteessa keskeisiin kilpailijamaihimme? Miten työn tuottavuuden vaikutus kustannuskilpailukykyyn eroaa eri maiden välillä? Miten Suomen vienti- ja tuontihinnat vertautuvat muihin kilpailijamaihin?

Korkeasti koulutetut yritysomistajat Suomessa – taustat, tulot ja yritykset
Selvitys kuvaa korkeasti koulutettuja osakeyhtiöiden omistajia ja heidän yrityksiään vuosina 2006–2021.

Akava Works -maahanmuuttokatsauksen verkkolähetys
Tervetuloa seuraamaan Akava Worksin maahanmuuttoaiheisen katsauksen esittelyä sekä ajankohtaista keskustelua keskiviikkona 27.9. Verkkolähetyksessä keskitytään erityisesti opiskelijoille myönnettyihin oleskelulupiin.

Psykososiaalinen kuormitus ja sitä koskeva sääntely Pohjoismaissa
Artikkeli on katsaus psykososiaalista kuormitusta ja sen hallintaa koskevaan lainsäädäntöön Pohjoismaissa. Tarkastelu kattaa Suomen lisäksi Ruotsin, Tanskan ja Norjan lainsäädännön.
Korkeakoulutettujen nuorten työelämänäkemykset pysyneet pitkälti samana – huoli työelämän vaatimuksista korostuu edelleen
Akava Works toteutti keväällä 2023 kyselyn, jossa selvitettiin 18–35-vuotiaiden näkemyksiä työelämästä, työssä jaksamisesta ja työelämäasenteita. Kysely oli toistomittaus vuonna 2018 tehdylle selvitykselle.